import os # To use terminal commands inside python for working on files and directories
# Data transformation libraries
import pandas as pd
import numpy as np
import copy
# Visualization libraries
import seaborn as sns
import matplotlib.pyplot as plt
# Scikit-learn packages
from sklearn.preprocessing import LabelEncoder # For label encoding the class labels
from sklearn.model_selection import ShuffleSplit
## Other libraries helpful for CV tasks
import cv2 # computer vision related packages for reading and playing with Image data
# Necessary packages for getting image editing capabilities
from PIL import Image
import PIL
from prettytable import PrettyTable # To format the results with good formatting
from zipfile import ZipFile # For extracting .zip files
import pickle # For exporting and importing the model files
# Necessary Pytorch libraries
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from torch.utils.data import Subset
import torchvision.transforms.functional as tf
import torch.optim as optim
import torchvision
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.models.detection import FasterRCNN_ResNet50_FPN_Weights
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
%matplotlib inline
# For plotting images inside the notebook
%matplotlib inlineMission Statement :
Identifying the car from the given entire dataset of ~16000 images using Computer Vision techniques.
Objectives :
Importing Necessary libraries and packages
from google.colab import drive
drive.mount('/content/drive')
os.chdir('/content/drive/MyDrive/GL_capstone_project')Mounted at /content/driveStep 1: Import the data.
Extracting the necessary zip files for the problem and if already extracted, skipping the file extraction
try:
with ZipFile('Car Images.zip', 'r') as z:
z.extractall()
with ZipFile('Annotations.zip', 'r') as z:
z.extractall()
except:
passStep 2: Map training and testing images to its classes.
# Get all the image names into a df and then merging above with images data --> Image name+image_name
# Creating the placeholders for storing the values while reading the images in train and test data
train_images_df=pd.DataFrame()
test_images_df=pd.DataFrame()
train_car_images_list=list()
train_car_images_path_list=list()
train_car_name_make_list=list()
test_car_images_list=list()
test_car_images_path_list=list()
test_car_name_make_list=list()
# Iterating through train images folder to get image_path, image_name and car_name_make_details
for sub_folder in os.listdir(os.path.join('car Images')):
if sub_folder =='Train Images':
for car_folder in os.listdir(os.path.join('car Images','Train Images')):
# Neglecting temporary folders created runtime and taking only the required folders
if car_folder!='.DS_Store' and car_folder!='.ipynb_checkpoints':
for car_image_name in os.listdir(os.path.join('car Images/Train Images',car_folder)):
if car_image_name.split('.')[1]=='jpg':
train_car_name_make_list.append(car_folder)
train_car_images_list.append(car_image_name)
train_car_images_path_list.append('car Images/Train Images/'+car_folder+'/'+car_image_name)
# Iterating through test images folder to get image_path, image_name and car_name_make_details
for sub_folder in os.listdir(os.path.join('car Images')):
if sub_folder =='Test Images':
for car_folder in os.listdir(os.path.join('car Images','Test Images')):
# Neglecting temporary folders created runtime and taking only the required folders
if car_folder!='.DS_Store' and car_folder!='.ipynb_checkpoints':
for car_image_name in os.listdir(os.path.join('car Images/Test Images',car_folder)):
if car_image_name.split('.')[1]=='jpg':
test_car_name_make_list.append(car_folder)
test_car_images_list.append(car_image_name)
test_car_images_path_list.append('car Images/Test Images/'+car_folder+'/'+car_image_name)
# Storing all the extracted information into the train and test dataframes created earlier
train_images_df['image_path']=train_car_images_path_list
train_images_df['image_name']=train_car_images_list
train_images_df['car_name_make']=train_car_name_make_list
print('train_images_df shape:',train_images_df.shape)
test_images_df['image_path']=test_car_images_path_list
test_images_df['image_name']=test_car_images_list
test_images_df['car_name_make']=test_car_name_make_list
print('test_images_df shape:',test_images_df.shape)train_images_df shape: (8144, 3)
test_images_df shape: (8041, 3)car_name_make_df=pd.read_csv('Car+names+and+make.csv',header=None)
car_name_make_df['image_class']=list(range(1,197))
car_name_make_df.rename(columns={0: 'car_name_make'}, inplace=True)
# In the car_name_make file,few car names are with '/', so replacing '/' with '-' to match with image folder names
car_name_make_df['car_name_make']=car_name_make_df['car_name_make'].apply(lambda x:x.replace('/','-'))
car_name_make_df=car_name_make_df[['image_class','car_name_make']]
print('Car names and make file shape:',car_name_make_df.shape)
# Merging with previous data frame on id='car_name_make' to get all details
# about train and test dataframes into a single entity
train_df=train_images_df.merge(car_name_make_df,on='car_name_make')
print('train_df shape:',train_df.shape)
test_df=test_images_df.merge(car_name_make_df,on='car_name_make')
print('test_df shape:',test_df.shape)Car names and make file shape: (196, 2)
train_df shape: (8144, 4)
test_df shape: (8041, 4)Viewing sample output of the dataframe in both train and test data
train_df.head(5)| image_path | image_name | car_name_make | image_class | |
|---|---|---|---|---|
| 0 | car Images/Train Images/Dodge Dakota Crew Cab ... | 03132.jpg | Dodge Dakota Crew Cab 2010 | 90 |
| 1 | car Images/Train Images/Dodge Dakota Crew Cab ... | 03984.jpg | Dodge Dakota Crew Cab 2010 | 90 |
| 2 | car Images/Train Images/Dodge Dakota Crew Cab ... | 08090.jpg | Dodge Dakota Crew Cab 2010 | 90 |
| 3 | car Images/Train Images/Dodge Dakota Crew Cab ... | 02012.jpg | Dodge Dakota Crew Cab 2010 | 90 |
| 4 | car Images/Train Images/Dodge Dakota Crew Cab ... | 07660.jpg | Dodge Dakota Crew Cab 2010 | 90 |
test_df.head(2)| image_path | image_name | car_name_make | image_class | |
|---|---|---|---|---|
| 0 | car Images/Test Images/GMC Canyon Extended Cab... | 02668.jpg | GMC Canyon Extended Cab 2012 | 122 |
| 1 | car Images/Test Images/GMC Canyon Extended Cab... | 01433.jpg | GMC Canyon Extended Cab 2012 | 122 |
Step 3: Map training and testing images to its annotations.
# Reading Annotations file for both both test and train folders to get image boundary and image_class details
train_annot_df=pd.read_csv(os.path.join('Annotations/Train Annotations.csv'))
print('Train_annotations shape:',train_annot_df.shape)
test_annot_df=pd.read_csv(os.path.join('Annotations/Test Annotation.csv'))
print('Test_annotations shape:',test_annot_df.shape)Train_annotations shape: (8144, 6)
Test_annotations shape: (8041, 6)# Merging with the previous dataframe with id as image_name+Image Name
train_df=train_df.merge(train_annot_df,left_on='image_name', right_on='Image Name')
# Dropping the unnecessary/repititive columns in the final dataframe
train_df.drop(['Image Name','Image class'],axis=1,inplace=True)
# Extracting few variables from train_df which can be helpful for EDA from car_name_make column
train_df['car_brand']=train_df['car_name_make'].apply(lambda x:x.split()[0])
train_df['car_make_yr']=train_df['car_name_make'].apply(lambda x:x.split()[-1])
print('Final_train_data shape:',train_df.shape)
test_df=test_df.merge(test_annot_df,left_on='image_name', right_on='Image Name')
# Dropping the unnecessary/repititive columns in the final dataframe
test_df.drop(['Image Name','Image class'],axis=1,inplace=True)
# Extracting few variables from test_df which can be helpful for EDA from car_name_make column
test_df['car_brand']=test_df['car_name_make'].apply(lambda x:x.split()[0])
test_df['car_make_yr']=test_df['car_name_make'].apply(lambda x:x.split()[-1])
print('Final_test_data shape:',test_df.shape)Final_train_data shape: (8144, 10)
Final_test_data shape: (8041, 10)Renaming the columns properly to get the correct vertices details for plotting the boundary box
# Renaming the image coordinates columns from the annotations file for better intuition and understanding
# Identified the co-ordinates with real images and then decided with these vertices details for the rectangle BB
train_df.rename(columns={'Bounding Box coordinates':'x1',
'Unnamed: 2':'y1',
'Unnamed: 3':'x2',
'Unnamed: 4':'y2'},inplace=True)
test_df.rename(columns={'Bounding Box coordinates':'x1',
'Unnamed: 2':'y1',
'Unnamed: 3':'x2',
'Unnamed: 4':'y2'},inplace=True)Viewing sample output and columns present in the final dataframe for both train and test data
This final data frame should have the following details: image_path, image_name, Annotations(BB-vertices details), image_class, car_name_make, car_brand & car_make_yr
train_df.head(2)| image_path | image_name | car_name_make | image_class | x1 | y1 | x2 | y2 | car_brand | car_make_yr | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | car Images/Train Images/Dodge Dakota Crew Cab ... | 03132.jpg | Dodge Dakota Crew Cab 2010 | 90 | 45 | 14 | 261 | 191 | Dodge | 2010 |
| 1 | car Images/Train Images/Dodge Dakota Crew Cab ... | 03984.jpg | Dodge Dakota Crew Cab 2010 | 90 | 8 | 19 | 289 | 180 | Dodge | 2010 |
train_df.columnsIndex(['image_path', 'image_name', 'car_name_make', 'image_class', 'x1', 'y1',
'x2', 'y2', 'car_brand', 'car_make_yr'],
dtype='object')test_df.head(2)| image_path | image_name | car_name_make | image_class | x1 | y1 | x2 | y2 | car_brand | car_make_yr | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | car Images/Test Images/GMC Canyon Extended Cab... | 02668.jpg | GMC Canyon Extended Cab 2012 | 122 | 13 | 66 | 477 | 228 | GMC | 2012 |
| 1 | car Images/Test Images/GMC Canyon Extended Cab... | 01433.jpg | GMC Canyon Extended Cab 2012 | 122 | 23 | 41 | 584 | 395 | GMC | 2012 |
Configuration
train_dataset = train_df.copy()
test_dataset = test_df.copy()
train_dir = "/content/drive/MyDrive/GL_capstone_project/car Images/Train Images"
test_dir = "/content/drive/MyDrive/GL_capstone_project/car Images/Test Images"
image_dir = "/content/drive/MyDrive/GL_capstone_project/"
np.random.seed(42)
torch.manual_seed(42)
device="cuda" if torch.cuda.is_available() else "cpu"
batch_size=4
learning_rate=3e-5
epochs=5
threshold=0.5
iou_threshold=0.8train_df['image_name'].nunique(), test_df['image_name'].nunique()
print(f'Unique image classes = {train_df.image_class.nunique()}')Unique image classes = 196Creating custom dataset
- Creating a new column called
image_idby replacing the string fromimage_name - Creating tensors as required by input to the model.
- We already have our bounding boxes as coordinates. So, we don’t need to perform any transformation there. However, the area for the bounding box is calculated based on \((x2-x1)*(y2-y1)\)
- We will use sklearn’s ShuffleSplit function here to split the images based on train and valid (80-20 split)
train_df['image_id'] = train_df['image_name'].str.replace(r'\.jpg$', '', regex=True)test_df['image_id'] = test_df['image_name'].str.replace(r'\.jpg$', '', regex=True)"""The input to the model is expected to be a list of tensors, each of shape [C, H, W],
one for each image, and should be in 0-1 range. Different images can have different
sizes.The behavior of the model changes depending if it is in training or evaluation
mode."""
class CarDataset(Dataset):
def __init__(self,dataframe,image_dir):
super().__init__()
self.dataframe=dataframe
self.img_list=sorted(self.dataframe["image_id"].unique())
self.img_dir=image_dir
def __len__(self):
return len(self.img_list)
def __getitem__(self,idx):
img_name=self.img_list[idx]
img_path=os.path.join(self.img_dir,self.dataframe["image_path"][idx])
img=cv2.imread(img_path)
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img=tf.to_tensor(img)
inter=self.dataframe[self.dataframe["image_id"]==self.img_list[idx]]
boxes=inter[["x1","y1","x2","y2"]].values
area=(boxes[:,2]-boxes[:,0])*(boxes[:,3]-boxes[:,1])
# converting bounding box from x0y0wh format to x0y0x1y1 format
# boxes[:,2]=boxes[:,0]+boxes[:,2]
# boxes[:,3]=boxes[:,1]+boxes[:,3]
labels=torch.ones((boxes.shape[0]),dtype=torch.int64)
iscrowd=torch.zeros((boxes.shape[0]),dtype=torch.uint8)
target={}
target["boxes"]=torch.as_tensor(boxes,dtype=torch.float32)
target["area"]=torch.as_tensor(area,dtype=torch.float32)
target["labels"]=labels
target["iscrowd"]=iscrowd
target["id"]=torch.tensor(idx)
return img,targettrain_ds=CarDataset(train_dataset,image_dir)
val_ds=CarDataset(train_dataset,image_dir)len(train_ds)8144ss=ShuffleSplit(n_splits=1,test_size=0.2,random_state=1)
indexs=range(len(train_ds))
for train_idx,val_idx in ss.split(indexs):
print(f"Train dataset length: {len(train_idx)}")
print(f"Validation dataset length: {len(val_idx)}")Train dataset length: 6515
Validation dataset length: 1629train_ds=Subset(train_ds,train_idx)
val_ds=Subset(val_ds,val_idx)len(train_ds), len(val_ds)(6515, 1629)def show(img,boxes):
boxes=boxes.detach().numpy().astype(np.int32)
sample=img.permute(1,2,0).numpy().copy()
for box in boxes:
cv2.rectangle(sample,(box[0], box[1]),(box[2], box[3]),(220, 0, 0), 3)
plt.axis("off");
plt.imshow(sample);DataLoader¶
def collate_fn(batch):
return tuple(zip(*batch))train_dl=DataLoader(train_ds,batch_size=batch_size,shuffle=True,num_workers=2,
pin_memory=True if torch.cuda.is_available else False,
collate_fn=collate_fn)
val_dl=DataLoader(val_ds,batch_size=batch_size,shuffle=False,num_workers=2,
pin_memory=True if torch.cuda.is_available else False,
collate_fn=collate_fn)Model
# load a model pre-trained on COCO
weights=FasterRCNN_ResNet50_FPN_Weights.DEFAULT
model=fasterrcnn_resnet50_fpn(weights=weights)
# replace the classifier with a new one, that has
# num_classes which is user-defined
# 1 class (person) + background
num_classes = 196
# get number of input features for the classifier
in_features=model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor=FastRCNNPredictor(in_channels=in_features,
num_classes=num_classes)
model.to(device)Downloading: "https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth" to /root/.cache/torch/hub/checkpoints/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
100%|██████████| 160M/160M [00:02<00:00, 79.0MB/s]FasterRCNN(
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
(backbone): BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): Conv2dNormActivation(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): Conv2dNormActivation(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): Conv2dNormActivation(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer_blocks): ModuleList(
(0-3): 4 x Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(extra_blocks): LastLevelMaxPool()
)
)
(rpn): RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
(roi_heads): RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=196, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=784, bias=True)
)
)
)for params in model.children():
print(params)GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(800,), max_size=1333, mode='bilinear')
)
BackboneWithFPN(
(body): IntermediateLayerGetter(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64, eps=0.0)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64, eps=0.0)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128, eps=0.0)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128, eps=0.0)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256, eps=0.0)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256, eps=0.0)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024, eps=0.0)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048, eps=0.0)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512, eps=0.0)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512, eps=0.0)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048, eps=0.0)
(relu): ReLU(inplace=True)
)
)
)
(fpn): FeaturePyramidNetwork(
(inner_blocks): ModuleList(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): Conv2dNormActivation(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): Conv2dNormActivation(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(3): Conv2dNormActivation(
(0): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer_blocks): ModuleList(
(0-3): 4 x Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(extra_blocks): LastLevelMaxPool()
)
)
RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=196, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=784, bias=True)
)
)"""ConvNet as fixed feature extractor: Here, we will freeze the weights for the backbone of
the network (resnet50 with feature pyramid network). The Regional Proposal network and
Region of Interest heads will be fine tuned using transfer learning."""
classification_head=list(model.children())[-2:]
for children in list(model.children())[:-2]:
for params in children.parameters():
params.requires_grad=False
parameters=[]
for heads in classification_head:
for params in heads.parameters():
parameters.append(params)
optimizer=optim.Adam(parameters,lr=learning_rate)
lr_scheduler=optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1,
patience=8, threshold=0.0001)
print(classification_head)[RegionProposalNetwork(
(anchor_generator): AnchorGenerator()
(head): RPNHead(
(conv): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
)
)
(cls_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(bbox_pred): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
), RoIHeads(
(box_roi_pool): MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], output_size=(7, 7), sampling_ratio=2)
(box_head): TwoMLPHead(
(fc6): Linear(in_features=12544, out_features=1024, bias=True)
(fc7): Linear(in_features=1024, out_features=1024, bias=True)
)
(box_predictor): FastRCNNPredictor(
(cls_score): Linear(in_features=1024, out_features=196, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=784, bias=True)
)
)]Training The Fine-Tuned Model
def get_lr(optimizer):
for params in optimizer.param_groups:
return params["lr"]loss_history={"training_loss":[],
"validation_loss":[]}
train_len=len(train_dl.dataset)
val_len=len(val_dl.dataset)
best_validation_loss=np.inf
best_weights=copy.deepcopy(model.state_dict())
for epoch in range(epochs):
training_loss=0.0
validation_loss=0.0
current_lr=get_lr(optimizer)
#During training, the model expects both the input tensors, as well as a targets
model.train()
for imgs,targets in train_dl:
imgs=[img.to(device) for img in imgs]
targets=[{k:v.to(device) for (k,v) in d.items()} for d in targets]
"""The model returns a Dict[Tensor] during training, containing the classification
and regression losses for both the RPN and the R-CNN."""
loss_dict=model(imgs,targets)
losses=sum(loss for loss in loss_dict.values())
training_loss+=losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
with torch.no_grad():
for imgs,targets in val_dl:
imgs=[img.to(device) for img in imgs]
targets=[{k:v.to(device) for (k,v) in d.items()} for d in targets]
"""The model returns a Dict[Tensor] during training, containing the classification
and regression losses for both the RPN and the R-CNN."""
loss_dict=model(imgs,targets)
losses=sum(loss for loss in loss_dict.values())
validation_loss+=losses.item()
lr_scheduler.step(validation_loss)
if current_lr!=get_lr(optimizer):
print("Loading best Model weights")
model.load_state_dict(best_weights)
if validation_loss<best_validation_loss:
best_validation_loss=validation_loss
best_weights=copy.deepcopy(model.state_dict())
print("Updating Best Model weights")
loss_history["training_loss"].append(training_loss/train_len)
loss_history["validation_loss"].append(validation_loss/val_len)
print(f"\n{epoch+1}/{epochs}")
print(f"Training Loss: {training_loss/train_len}")
print(f"Validation_loss: {validation_loss/val_len}")
print("\n"+"*"*50)Updating Best Model weights
1/5
Training Loss: 0.5091633841704151
Validation_loss: 0.4923232738008669
**************************************************
Updating Best Model weights
2/5
Training Loss: 0.34851808806999957
Validation_loss: 0.33369734506891724
**************************************************
Updating Best Model weights
3/5
Training Loss: 0.2804957070411487
Validation_loss: 0.29477986226863406
**************************************************
Updating Best Model weights
4/5
Training Loss: 0.2661970856332907
Validation_loss: 0.285527507111915
**************************************************
5/5
Training Loss: 0.26277425953473665
Validation_loss: 0.28928613928909896
**************************************************sns.lineplot(x=range(epochs),y=loss_history["training_loss"],label="Train Losses");
sns.lineplot(x=range(epochs),y=loss_history["validation_loss"],label="Validation Losses");
plt.title("Training Validation Datasets Losses Plot");
plt.legend();
plt.savefig("3.jpg")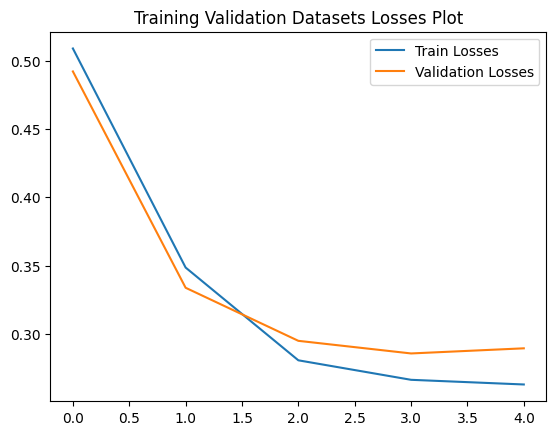
Model Save
model_weights_file="model.pth"
torch.save(best_weights,model_weights_file)Next Steps:
- Inference on the model
- Performing Data Augmentation, hyperparameter-tuning, different backbone architectures to compare losses.