This section of code performs initial data preprocessing and exploration tasks:
Reading the CSV file: It reads the dataset from a CSV file named “chronic_kidney_disease_full.csv” and selects specific columns.
Removing single quotes from column names: It removes single quotes from the column names to ensure consistency and ease of access.
Checking for duplicates: It checks for any duplicate rows in the dataset to ensure data integrity.
Storing the original dataset: It creates a copy of the original dataset for further exploratory data analysis (EDA) without affecting the original data.
Show the code
# Importing pandasimport pandas as pd# Reading the CSV file and selecting columnschronic_kidney_disease_df = pd.read_csv("chronic_kidney_disease_full.csv", usecols=range(1, 26))# Displaying the first few rowschronic_kidney_disease_df.head()# Removing single quotes from column nameschronic_kidney_disease_df.columns = chronic_kidney_disease_df.columns.str.replace("'", "")# Displaying the first few rows again to verify changeschronic_kidney_disease_df.head()
age
bp
sg
al
su
rbc
pc
pcc
ba
bgr
...
pcv
wbcc
rbcc
htn
dm
cad
appet
pe
ane
class
0
48
80
1.020
1
0
?
normal
notpresent
notpresent
121
...
44
7800
5.2
yes
yes
no
good
no
no
ckd
1
7
50
1.020
4
0
?
normal
notpresent
notpresent
?
...
38
6000
?
no
no
no
good
no
no
ckd
2
62
80
1.010
2
3
normal
normal
notpresent
notpresent
423
...
31
7500
?
no
yes
no
poor
no
yes
ckd
3
48
70
1.005
4
0
normal
abnormal
present
notpresent
117
...
32
6700
3.9
yes
no
no
poor
yes
yes
ckd
4
51
80
1.010
2
0
normal
normal
notpresent
notpresent
106
...
35
7300
4.6
no
no
no
good
no
no
ckd
5 rows × 25 columns
Show the code
# Checking for duplicates in the dataframeduplicates = chronic_kidney_disease_df[chronic_kidney_disease_df.duplicated()]# Storing the original dataset for further exploratory data analysis (EDA)chronic_kidney_disease_df_old = chronic_kidney_disease_df.copy(deep=True)# Displaying the first few rows of the original dataset copychronic_kidney_disease_df_old.head()
age
bp
sg
al
su
rbc
pc
pcc
ba
bgr
...
pcv
wbcc
rbcc
htn
dm
cad
appet
pe
ane
class
0
48
80
1.020
1
0
?
normal
notpresent
notpresent
121
...
44
7800
5.2
yes
yes
no
good
no
no
ckd
1
7
50
1.020
4
0
?
normal
notpresent
notpresent
?
...
38
6000
?
no
no
no
good
no
no
ckd
2
62
80
1.010
2
3
normal
normal
notpresent
notpresent
423
...
31
7500
?
no
yes
no
poor
no
yes
ckd
3
48
70
1.005
4
0
normal
abnormal
present
notpresent
117
...
32
6700
3.9
yes
no
no
poor
yes
yes
ckd
4
51
80
1.010
2
0
normal
normal
notpresent
notpresent
106
...
35
7300
4.6
no
no
no
good
no
no
ckd
5 rows × 25 columns
Handling Missing Values and Exploring Categorical Data:
The following tasks are performed 1. Replacing missing values: It replaces missing values denoted by ‘?’ with NaN (Not a Number) using the replace() function.
Displaying the first few rows: It displays the first few rows of the dataset after replacing missing values to verify the changes.
Defining categorical and numerical columns: It defines lists of column names for categorical and numerical data based on the dataset’s characteristics.
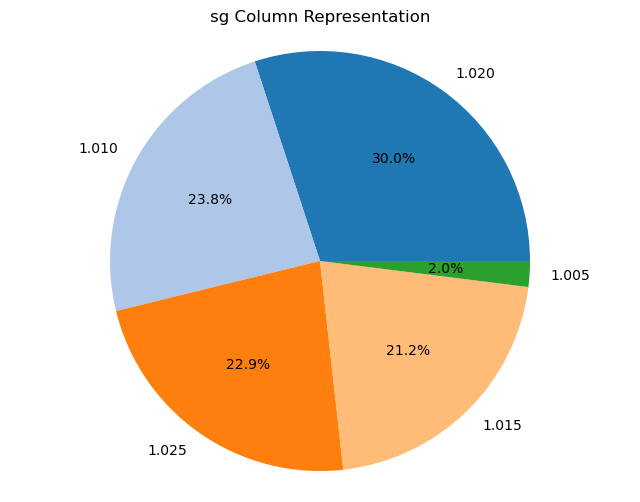
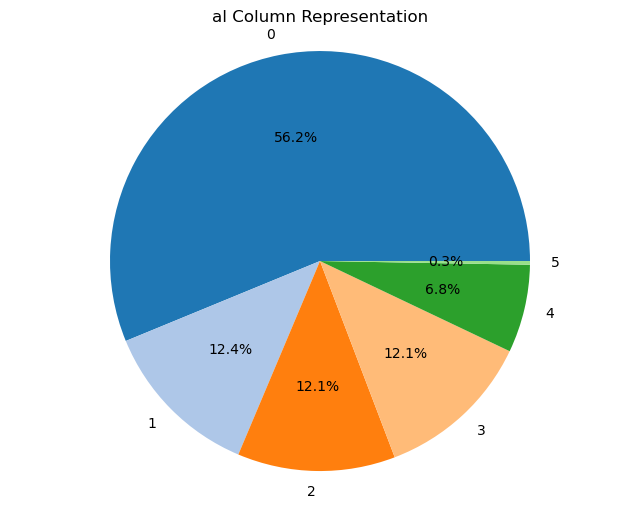
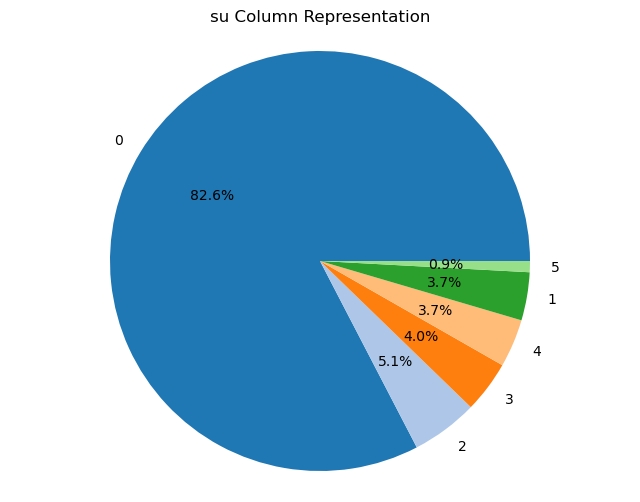
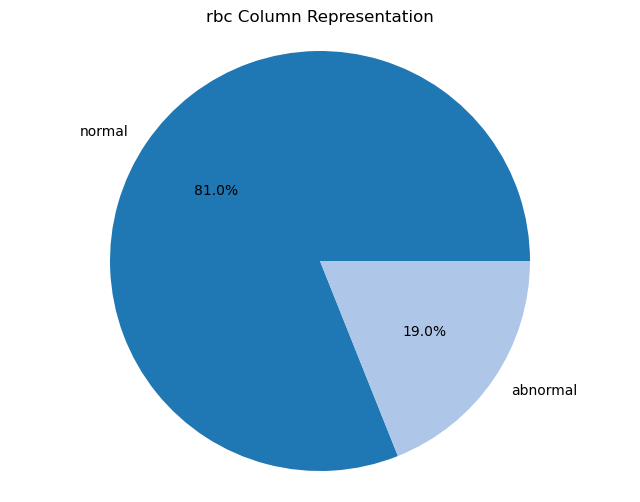
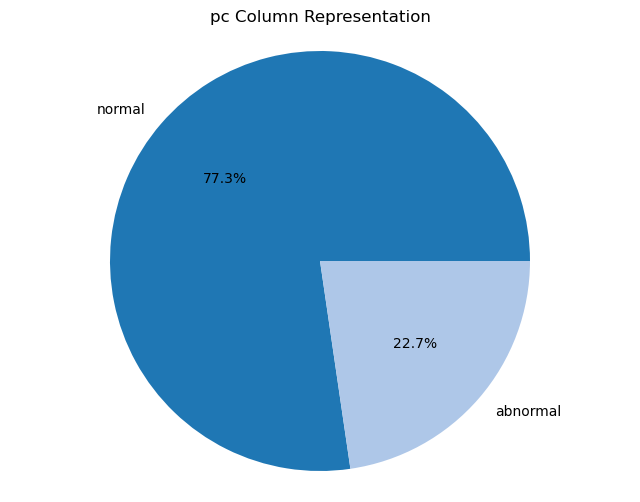
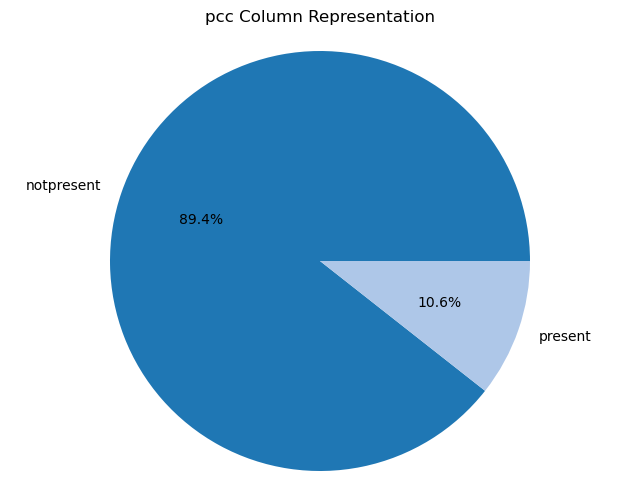
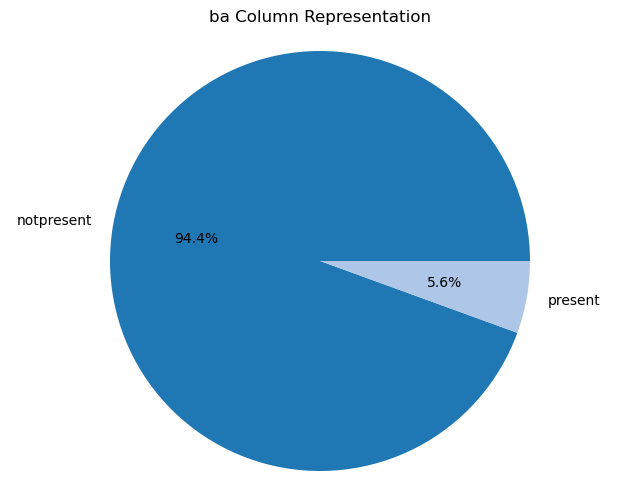
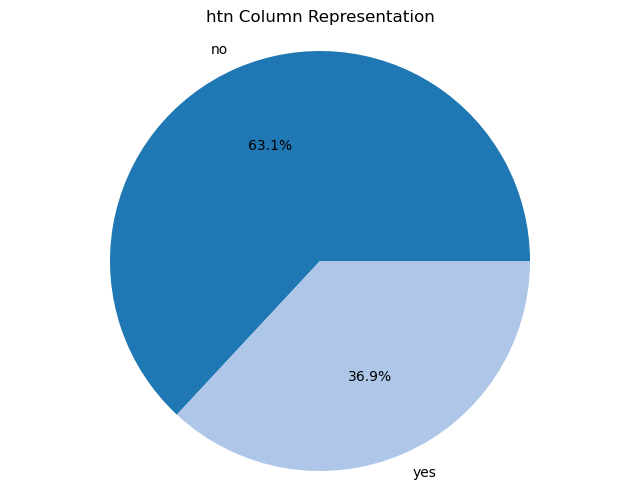
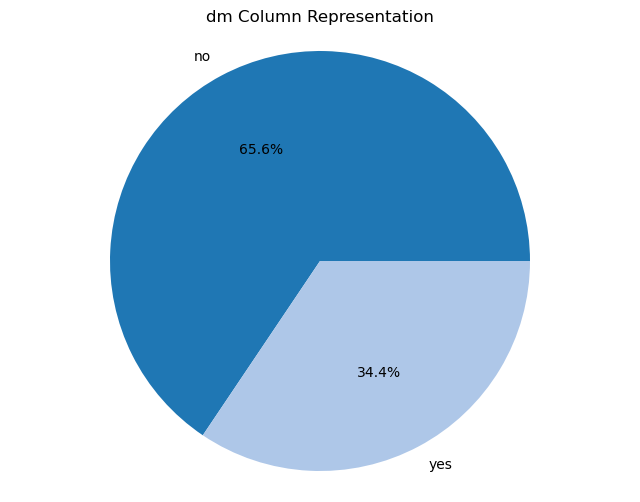
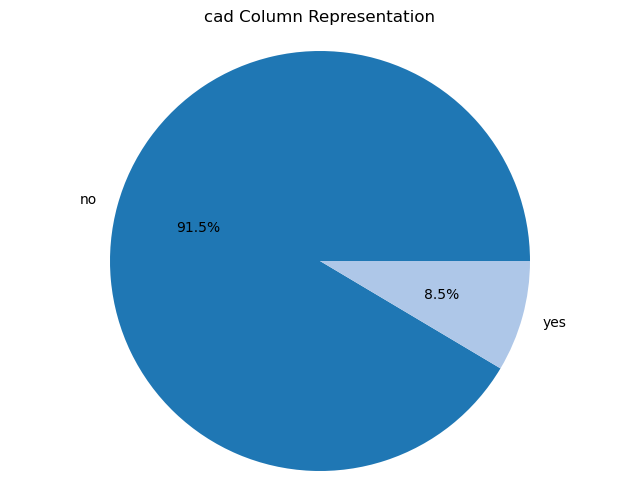
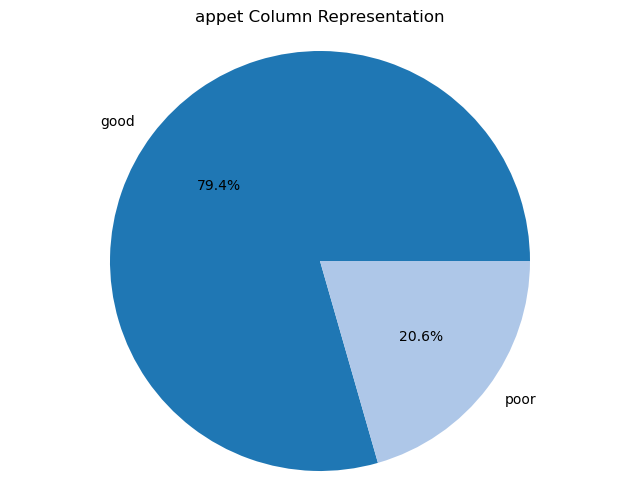
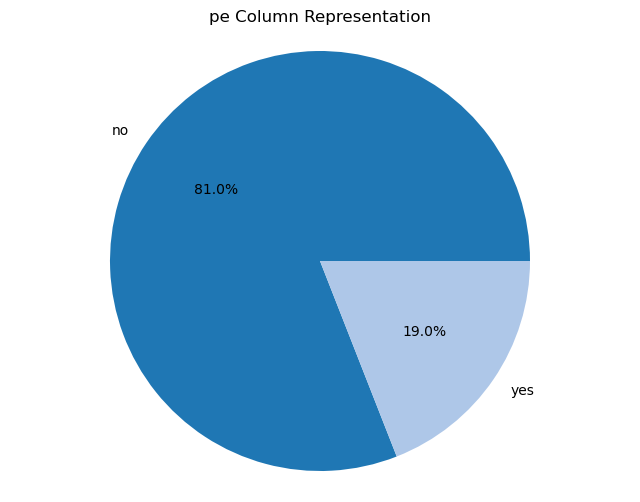
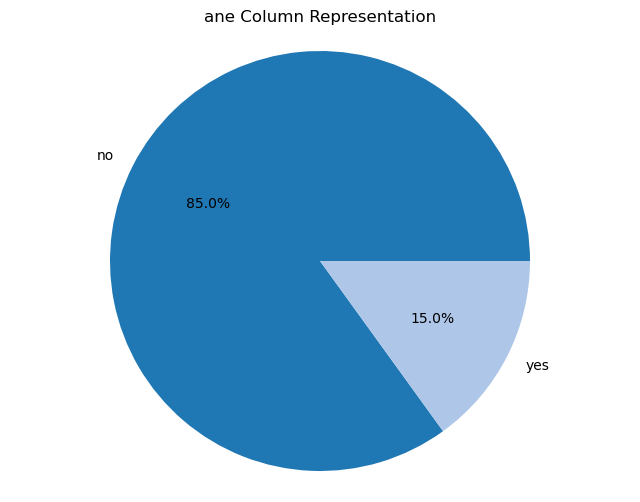
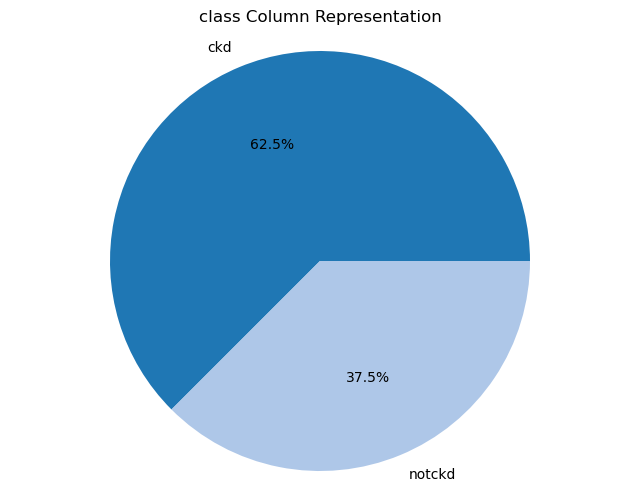
Creating pie charts for categorical columns: It iterates over the categorical columns and creates pie charts to visualize the distribution of each categorical variable. Each pie chart represents the proportions of different categories within a column.
Show the code
# Replacing missing values (i.e., '?') with NaNchronic_kidney_disease_df = chronic_kidney_disease_df.replace("?", np.NaN)# Displaying the first few rows after replacing missing valueschronic_kidney_disease_df.head()# Columns with nominal datacategorical_cols = ["sg", "al", "su", "rbc", "pc", "pcc", "ba", "htn", "dm", "cad", "appet", "pe", "ane", "class"]# Columns with numerical datanon_categorical_cols = ["age", "bp", "ba", "bgr", "bu", "sc", "sod", "pot", "hemo", "pcv", "wbcc", "rbcc"]
Show the code
import matplotlib.pyplot as plt# Iterate over categorical columns and create pie chartsfor pie_col_name in categorical_cols:# Calculate value counts for the current column counts = chronic_kidney_disease_df[pie_col_name].value_counts()# Plot pie chart plt.figure(figsize=(8, 6)) plt.pie(counts, labels=counts.index, autopct='%1.1f%%', colors=plt.cm.tab20.colors) plt.title(f"{pie_col_name} Column Representation") plt.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle plt.show()
Encoding Categorical Data and Imputing Missing Values:
We now perform encoding using LabelEncoding and Impute using KNN 1. Encoding Categorical Data: It defines a function encode to encode non-null data in categorical columns using LabelEncoder. This ensures that categorical data is represented numerically for machine learning algorithms.
Applying Encoding Function: It applies the encode function to the categorical columns in the dataset, converting them to numerical representation using LabelEncoder, and then converts them to the categorical data type.
Imputing Missing Values: It defines a function impute to impute missing values using KNN imputer. The function performs imputation separately for categorical and numerical columns, ensuring appropriate data types for imputed values.
Applying Imputation Function: It iterates over columns in the dataset and applies the impute function to impute missing values using KNN imputer, handling both categorical and numerical columns appropriately.
Each step is accompanied by comments explaining its purpose and functionality. This sub-heading and explanation provide context and clarity for the code section.
Show the code
def encode(data):"""Function to encode non-null data"""# Retain only non-null values data_no_null = np.array(data.dropna())# Encode data encoded_data = label_encoder.fit_transform(data_no_null)# Assign back encoded values to non-null values data.loc[data.notnull()] = np.squeeze(encoded_data)return data# Apply encoding function to categorical columnschronic_kidney_disease_df[categorical_cols] = chronic_kidney_disease_df[categorical_cols].apply(encode)# Convert categorical columns to categorical data typechronic_kidney_disease_df[categorical_cols] = chronic_kidney_disease_df[categorical_cols].astype("category")# Display the first few rowschronic_kidney_disease_df.head()
age
bp
sg
al
su
rbc
pc
pcc
ba
bgr
...
pcv
wbcc
rbcc
htn
dm
cad
appet
pe
ane
class
0
48
80
3
1
0
NaN
1
0
0
121
...
44
7800
5.2
1
1
0
0
0
0
0
1
7
50
3
4
0
NaN
1
0
0
NaN
...
38
6000
NaN
0
0
0
0
0
0
0
2
62
80
1
2
3
1
1
0
0
423
...
31
7500
NaN
0
1
0
1
0
1
0
3
48
70
0
4
0
1
0
1
0
117
...
32
6700
3.9
1
0
0
1
1
1
0
4
51
80
1
2
0
1
1
0
0
106
...
35
7300
4.6
0
0
0
0
0
0
0
5 rows × 25 columns
Show the code
def impute(data, col):"""Function to impute null data"""# Perform imputation using KNN imputer result = knn_imputer.fit_transform(data)# Convert imputed values to integers if the column is categoricalif col in categorical_cols:return result.astype(int)# Round imputed values to two decimal places for numerical columnsreturn np.round(result, 2)# Iterate over columns and apply imputation functionfor col in chronic_kidney_disease_df.columns: chronic_kidney_disease_df[[col]] = impute(chronic_kidney_disease_df[[col]], col)# Display the first few rowschronic_kidney_disease_df.head()
age
bp
sg
al
su
rbc
pc
pcc
ba
bgr
...
pcv
wbcc
rbcc
htn
dm
cad
appet
pe
ane
class
0
48.0
80.0
3
1
0
0
1
0
0
121.00
...
44.0
7800.0
5.20
1
1
0
0
0
0
0
1
7.0
50.0
3
4
0
0
1
0
0
148.04
...
38.0
6000.0
4.71
0
0
0
0
0
0
0
2
62.0
80.0
1
2
3
1
1
0
0
423.00
...
31.0
7500.0
4.71
0
1
0
1
0
1
0
3
48.0
70.0
0
4
0
1
0
1
0
117.00
...
32.0
6700.0
3.90
1
0
0
1
1
1
0
4
51.0
80.0
1
2
0
1
1
0
0
106.00
...
35.0
7300.0
4.60
0
0
0
0
0
0
0
5 rows × 25 columns
Visualizing Correlation Matrix
Show the code
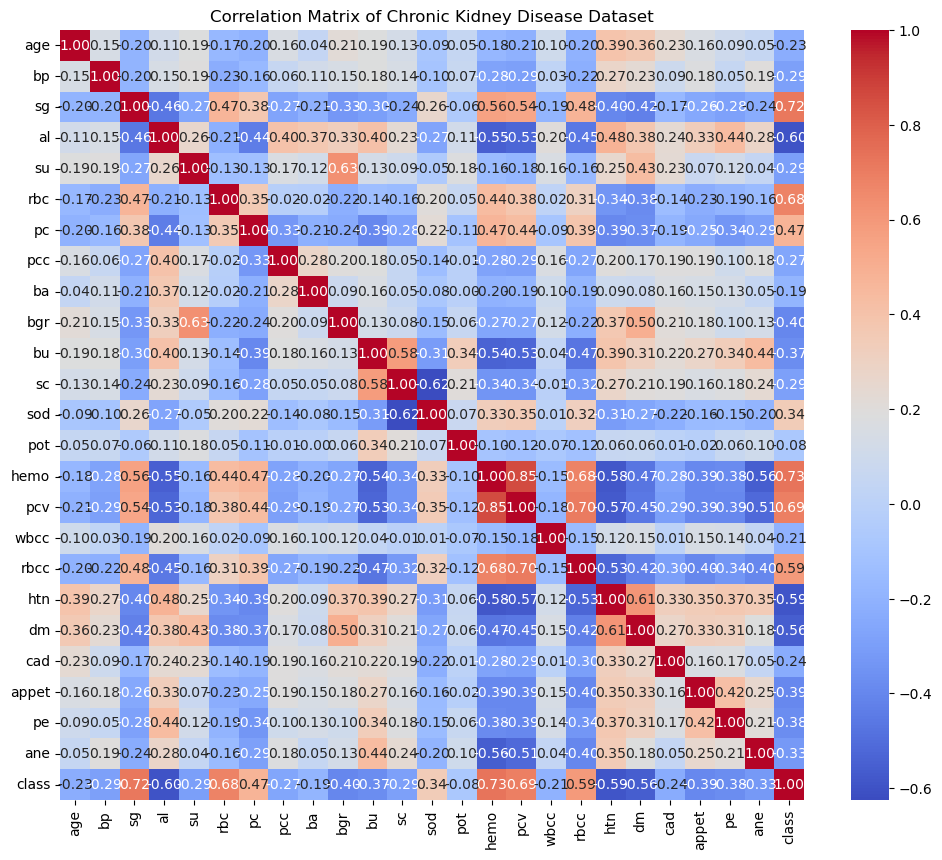
# Correlation Matrixplt.figure(figsize=(12, 10)) # Adjusting the figure size for better visibilitysns.heatmap( chronic_kidney_disease_df.corr(), # Plotting the correlation matrix annot=True, # Adding annotations to the cells with correlation values fmt=".2f", # Formatting the annotations to two decimal places cmap="coolwarm", # Choosing a color map for better visualization)# Rotating x and y axis labels for better readabilityplt.xticks(rotation=90)plt.yticks(rotation=0)plt.title("Correlation Matrix of Chronic Kidney Disease Dataset") # Adding a title to the plotplt.show()
Understanding Relationships with Correlation Matrix
This section of code generates a heatmap to visualize the correlation matrix of the Chronic Kidney Disease dataset. Each cell in the heatmap represents the correlation coefficient between two variables, with values ranging from -1 to 1.
The heatmap function from the seaborn library is used to plot the correlation matrix, with annotations showing the correlation values formatted to two decimal places.
The color map coolwarm is chosen for better visualization of positive and negative correlations, where warmer colors indicate positive correlations and cooler colors indicate negative correlations.
X and Y axis labels are rotated for better readability.
Finally, a title “Correlation Matrix of Chronic Kidney Disease Dataset” is added to the plot.
Understanding Numerical Data and Data Splitting
Show the code
# Understanding numerical data for outliersnumerical_data_summary = chronic_kidney_disease_df[non_categorical_cols].describe()print(numerical_data_summary)# Fit and transform the scaler to the training datachronic_kidney_disease_df[non_categorical_cols] = scaler.fit_transform( chronic_kidney_disease_df[non_categorical_cols])
age bp ba bgr bu
count 400.000000 400.000000 4.000000e+02 4.000000e+02 4.000000e+02 \
mean 0.000000 0.000000 4.440892e-17 3.552714e-17 -1.776357e-17
std 1.001252 1.001252 1.001252e+00 1.001252e+00 1.001252e+00
min -2.918726 -1.966582 -2.412490e-01 -1.687487e+00 -1.136146e+00
25% -0.559363 -0.480637 -2.412490e-01 -6.297693e-01 -6.181086e-01
50% 0.148445 0.131202 -2.412490e-01 -2.950484e-01 -2.727503e-01
75% 0.738286 0.262336 -2.412490e-01 2.628362e-02 8.784442e-02
max 2.271871 7.692065 4.145096e+00 4.578487e+00 6.776622e+00
sc sod pot hemo pcv
count 400.000000 400.000000 4.000000e+02 4.000000e+02 400.000000 \
mean 0.000000 0.000000 4.440892e-18 -7.105427e-17 0.000000
std 1.001252 1.001252 1.001252e+00 1.001252e+00 1.001252
min -0.476315 -14.471063 -7.555599e-01 -3.475004e+00 -3.670817
25% -0.387196 -0.275110 -2.229378e-01 -6.089339e-01 -0.599898
50% -0.298077 0.000106 7.634249e-04 1.142742e-03 -0.000454
75% -0.000419 0.377577 6.112726e-02 7.734149e-01 0.628470
max 12.998506 2.770764 1.504556e+01 1.943804e+00 1.856837
wbcc rbcc
count 4.000000e+02 4.000000e+02
mean 3.552714e-17 -7.105427e-17
std 1.001252e+00 1.001252e+00
min -2.462684e+00 -3.107812e+00
25% -5.678911e-01 -2.481638e-01
50% -7.142676e-07 2.055372e-03
75% 3.943861e-01 4.667482e-01
max 7.140247e+00 3.922156e+00
Show the code
# Display the first few rows after scalingchronic_kidney_disease_df.head()
age
bp
sg
al
su
rbc
pc
pcc
ba
bgr
...
pcv
wbcc
rbcc
htn
dm
cad
appet
pe
ane
class
0
-0.205459
0.262336
3
1
0
0
1
0
-0.241249
-0.361993
...
0.628470
-0.240518
0.585900
1
1
0
0
0
0
0
1
-2.623805
-1.966582
3
4
0
0
1
0
-0.241249
0.000042
...
-0.108551
-0.954786
0.002055
0
0
0
0
0
0
0
2
0.620318
0.262336
1
2
3
1
1
0
-0.241249
3.681436
...
-0.968408
-0.359563
0.002055
0
1
0
1
0
1
0
3
-0.205459
-0.480637
0
4
0
1
0
1
-0.241249
-0.415548
...
-0.845571
-0.677015
-0.963076
1
0
0
1
1
1
0
4
-0.028507
0.262336
1
2
0
1
1
0
-0.241249
-0.562825
...
-0.477061
-0.438926
-0.129012
0
0
0
0
0
0
0
5 rows × 25 columns
Show the code
# Splitting the dataset into training and testing setsX_train, X_test, y_train, y_test = train_test_split( chronic_kidney_disease_df.drop(columns="class", axis=1), # Features (X) chronic_kidney_disease_df["class"], # Target variable (y) test_size=0.2, # Ratio of testing set random_state=8, # Random seed for reproducibility)# Displaying the shapes of training and testing setsprint("Shape of X_train:", X_train.shape)print("Shape of X_test:", X_test.shape)
Shape of X_train: (320, 24)
Shape of X_test: (80, 24)
We performed the following here:
Summary Statistics for Numerical Data: It generates summary statistics (mean, standard deviation, min, max, quartiles) for numerical columns in the dataset using the describe() function.
Scaling Numerical Data: It scales the numerical features using the StandardScaler. This step is essential for many machine learning algorithms to ensure that all features contribute equally to the model fitting process.
Data Splitting: It splits the preprocessed dataset into training and testing sets using train_test_split from sklearn.model_selection. This step is crucial for evaluating the performance of machine learning models on unseen data.
Displaying Shapes of Training and Testing Sets: It prints the shapes of the training and testing sets to verify that the splitting was successful. This information helps ensure that the dataset has been partitioned correctly for model training and evaluation.
Model Training and Evaluation with GridSearchCV
This section of code performs the following tasks:
Defining Models and Parameters: It defines two classification models, Decision Tree Classifier and Random Forest Classifier, along with their respective parameter grids for hyperparameter tuning.
GridSearchCV: It iterates over each model and performs hyperparameter tuning using GridSearchCV with 10-fold cross-validation. The best parameters found by GridSearchCV are printed for each model.
Model Evaluation: It evaluates the best model obtained from GridSearchCV on both training and testing data. Evaluation metrics such as accuracy, ROC AUC score, precision, recall, and F1 score are calculated and printed. Confusion matrix and classification report are also displayed for better understanding of model performance.
Storing Model Details: It stores the model name, evaluation metrics, and the best model itself in a DataFrame for further analysis and comparison.
This comprehensive approach ensures that the models are tuned for optimal performance and thoroughly evaluated before making any predictions on unseen data.
Show the code
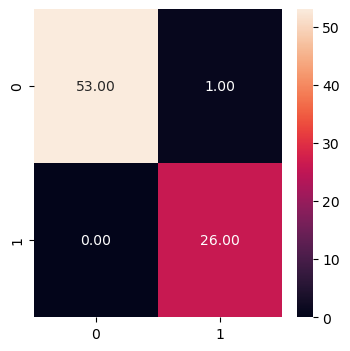
train_model_lists = []model_details = {"DecisionTree_Classifier": DecisionTreeClassifier(random_state=42),"RandomForest_Classifier": RandomForestClassifier(random_state=42),}param_details = {"DecisionTree_Classifier": {"ccp_alpha": [0.1, 0.01, 0.001],"max_depth": list(range(1, 10)),"criterion": ["gini", "entropy"], },"RandomForest_Classifier": {"n_estimators": list(range(10, 50, 5)),"max_depth": list(range(1, 10)),"criterion": ["gini", "entropy"], },}for model_name, model in model_details.items():print(f"Running GridSearchCV for {model_name}.") grid_search = GridSearchCV( model, param_details[model_name], cv=10, n_jobs=-1, refit=True ) grid_search.fit(X_train, y_train)print(f"GridSearchCV best params for {model_name} are {grid_search.best_params_}") best_model = grid_search.best_estimator_ best_model.fit(X_train, y_train) y_pred_train = best_model.predict(X_train) y_pred_test = best_model.predict(X_test) train_model_lists.append([ model_name, accuracy_score(y_train, y_pred_train), accuracy_score(y_test, y_pred_test), roc_auc_score(y_test, y_pred_test), precision_score(y_test, y_pred_test), recall_score(y_test, y_pred_test), f1_score(y_test, y_pred_test), best_model ])print(f"Best model determined: {best_model}")# Plot confusion matrix plt.figure(figsize=(4, 4)) sns.heatmap(confusion_matrix(y_test, y_pred_test), annot=True, fmt=".2f") plt.show()# Print classification reportprint("\nClassification Report:\n", classification_report(y_test, y_pred_test))print(f"GridSearchCV for {model_name} completed.\n")# Create a DataFrame to store model detailsmodel_df = pd.DataFrame( train_model_lists, columns=["Model_Name","Train_Accuracy","Test_Accuracy","ROC_AUC","Precision","Recall","F1 Score","Model", ]).sort_values(by=["Recall", "F1 Score"], ascending=False)model_df
Running GridSearchCV for DecisionTree_Classifier.
GridSearchCV best params for DecisionTree_Classifier are {'ccp_alpha': 0.001, 'criterion': 'entropy', 'max_depth': 6}
Best model determined: DecisionTreeClassifier(ccp_alpha=0.001, criterion='entropy', max_depth=6,
random_state=42)
Classification Report:
precision recall f1-score support
0 1.00 0.98 0.99 54
1 0.96 1.00 0.98 26
accuracy 0.99 80
macro avg 0.98 0.99 0.99 80
weighted avg 0.99 0.99 0.99 80
GridSearchCV for DecisionTree_Classifier completed.
Running GridSearchCV for RandomForest_Classifier.
GridSearchCV best params for RandomForest_Classifier are {'criterion': 'gini', 'max_depth': 6, 'n_estimators': 45}
Best model determined: RandomForestClassifier(max_depth=6, n_estimators=45, random_state=42)
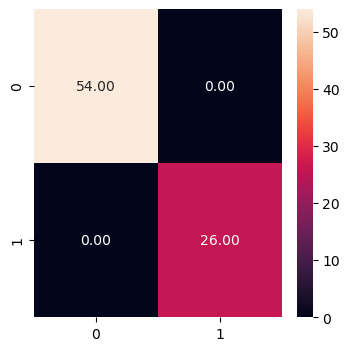
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 54
1 1.00 1.00 1.00 26
accuracy 1.00 80
macro avg 1.00 1.00 1.00 80
weighted avg 1.00 1.00 1.00 80
GridSearchCV for RandomForest_Classifier completed.
Model_Name
Train_Accuracy
Test_Accuracy
ROC_AUC
Precision
Recall
F1 Score
Model
1
RandomForest_Classifier
1.0
1.0000
1.000000
1.000000
1.0
1.000000
(DecisionTreeClassifier(max_depth=6, max_featu...
0
DecisionTree_Classifier
1.0
0.9875
0.990741
0.962963
1.0
0.981132
DecisionTreeClassifier(ccp_alpha=0.001, criter...
The classification report provides a summary of the model’s performance on the testing dataset:
Precision: Precision measures the accuracy of the positive predictions made by the model. A high precision indicates that the model made fewer false positive predictions.
Recall: Recall (also known as sensitivity) measures the ability of the model to correctly identify all positive instances. A high recall indicates that the model did not miss many positive instances.
F1-score: F1-score is the harmonic mean of precision and recall. It provides a balance between precision and recall. A high F1-score indicates both high precision and high recall.
Support: Support refers to the number of actual occurrences of each class in the testing dataset.
In the provided classification report:
For class 0:
Precision, recall, and F1-score are all 1.00, indicating perfect performance.
Support is 54, meaning there are 54 instances of class 0 in the testing dataset.
For class 1:
Precision, recall, and F1-score are all 1.00, also indicating perfect performance.
Support is 26, meaning there are 26 instances of class 1 in the testing dataset.
Accuracy: Overall accuracy of the model is 1.00, meaning all predictions made by the model are correct.
Saving and Loading the Best Model
This section of code performs the following tasks:
Get the Best Model: It retrieves the best model from the DataFrame containing model details.
Save the Best Model to a Pickle File: It saves the best model to a pickle file named “model.pkl” using Python’s pickle.dump() function.
Load the Saved Model: It loads the saved model from the pickle file using Python’s pickle.load() function.
Print the Loaded Model: It prints the loaded model to verify that the saving and loading process was successful.
Using pickle allows the model to be serialized and stored as a binary file, making it easy to save and load machine learning models for future use without retraining.
Show the code
# Get the best model from the DataFramebest_model = model_df.head(1)["Model"].values[0]best_model
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
# Save the best model to a pickle filewithopen("model.pkl", "wb") asfile: pickle.dump(best_model, file)# Load the saved model from the pickle filewithopen("model.pkl", "rb") asfile: loaded_model = pickle.load(file)# Print the loaded model to verifyprint(loaded_model)
Limited Dataset Size: The ‘Chronic Kidney Disease’ dataset contains a small number of records, which may limit the effectiveness of our model due to insufficient data for learning.
Class Imbalance: There is an observable imbalance between the classes in the dataset, which may affect the model’s ability to accurately predict minority classes.
Imputation Impact: The imputation of missing values in the dataset may introduce noise or bias into the model, as the imputed values may not accurately represent the true values.
Need for Data Augmentation: To address the limited dataset size, techniques such as Synthetic Minority Over-sampling Technique (SMOTE) could be considered to artificially increase the number of records.
Limited Generalization: The model’s ability to generalize to unseen data may be constrained by the small and potentially biased dataset, limiting its practical utility in real-world scenarios.
Uncertainty in Predictions: Due to the small dataset size and potential data quality issues, the model’s predictions may have higher uncertainty and may not be reliable in all cases.
Selvaraj, N. (2022). Hyperparameter Tuning Using Grid Search and Random Search in Python. [online] KDnuggets. Available at: https://www.kdnuggets.com/2022/10/hyperparameter-tuning-grid-search-random-search-python.html.